Protect your Kubernetes Operator from OOMKill
I was auditing the Kubeflow Spark Operator’s cache configuration when something caught my eye. Pods had a proper label selector filtering what the informer stores. ConfigMaps had an empty {}. That empty config means the informer watches and caches every single ConfigMap in every namespace, cluster-wide, in memory.
That’s a problem. A big one. Any user with standard edit permissions can create enough ConfigMaps to OOMKill the operator, take it into CrashLoopBackOff, and deny service to every Spark workload on the cluster. No elevated privileges required.
This is Part 1 of a two-part series. This post covers the vulnerability, why common defenses don’t work, and the full fix. Part 2 catalogs five anti-patterns that cause this across the controller-runtime ecosystem.
How informer caches work
If you write Kubernetes operators with controller-runtime, you already know the basics, but the details matter here.
When your operator needs to know about objects in the cluster (Pods, ConfigMaps, Secrets), it doesn’t query the API server every time. That would be slow and create too much load. Instead, it sets up an informer: a component that does a full LIST of every matching object at startup, then opens a persistent WATCH connection to receive changes in real time.
Every object the informer sees gets deserialized into a full Go struct and stored in an in-memory cache. Subsequent client.Get() calls read from this cache instead of hitting the API server. Fast and efficient.
The problem is the word “every.” If you set up an informer without filters, it caches every single object of that type. Every ConfigMap. Every Secret. Every namespace. All in memory.
The informer does a full LIST at startup, pulls every matching object into memory, then maintains that cache via a WATCH stream. Without a label selector or namespace restriction, “matching” means “all of them.” On a production cluster with thousands of ConfigMaps across hundreds of namespaces, that’s a lot of memory for objects your operator will never look at.
Here’s the critical detail: the objects aren’t stored as compressed bytes or wire-format protobuf. Each object gets fully deserialized into a Go struct. A corev1.ConfigMap struct includes map headers, string headers, slice headers, and pointer indirection for every field. The in-memory representation of a 900KB ConfigMap is significantly larger than 900KB. Runtime overhead from Go’s garbage collector metadata, map bucket allocation, and string interning adds up fast when you’re caching thousands of objects.
The vulnerable code
Here’s what the Spark Operator’s cache configuration looked like:
ByObject: map[client.Object]cache.ByObject{
&corev1.Pod{}: {
Label: labels.SelectorFromSet(labels.Set{
"sparkoperator.k8s.io/launched-by-spark-operator": "true",
}),
},
&corev1.ConfigMap{}: {}, // caches ALL ConfigMaps everywhere
}Pods are filtered correctly. Only pods with the Spark operator label get cached. Good.
ConfigMaps have an empty {}. No label selector, no namespace filter, no field selector. The informer watches and caches every ConfigMap in the entire cluster. The Spark Operator only creates a handful of ConfigMaps (Prometheus configs, Spark driver configs), but the cache doesn’t know that. It dutifully stores every ConfigMap it finds.
This is a bad default in controller-runtime. An empty cache.ByObject{} looks harmless. It looks like “no special configuration needed.” What it actually means is “create a cluster-wide informer with no filters.”
How any user can exploit this
No special permissions are needed. Any user with the standard edit ClusterRole, which is the default for developers and data scientists in multi-tenant clusters, can create ConfigMaps in their assigned namespaces. Each ConfigMap can be up to 1MB (the Kubernetes API server enforces this limit).
The attack is straightforward. Generate a 900KB payload:
dd if=/dev/urandom bs=1024 count=900 2>/dev/null | base64 > /tmp/payload.txt
truncate -s 921600 /tmp/payload.txtCreate 10 test namespaces and flood them with 700 ConfigMaps:
for i in $(seq 1 10); do
oc create ns oom-test-$i
done
for i in $(seq 1 700); do
ns="oom-test-$(( (i % 10) + 1 ))"
oc create configmap "oom-payload-$i" \
--from-file=data=/tmp/payload.txt -n "$ns" 2>/dev/null &
[ $((i % 5)) -eq 0 ] && wait
done
waitThe math: 700 ConfigMaps at 900KB each is about 630MB of raw data. But the informer doesn’t store raw bytes. It deserializes each ConfigMap into a typed Go struct with map headers, string headers, and pointer indirection. The actual in-memory representation is larger than the serialized wire format.
With a typical 512 MiB memory limit on the operator pod, it gets OOMKilled. The kubelet restarts it. On restart, the informer does a full re-LIST (which pulls all 700 ConfigMaps back into memory), exceeds the limit again, and crashes. This repeats until the pod enters CrashLoopBackOff. Complete denial-of-service for every Spark workload on the cluster.
Within 30-60 seconds of the flood completing:
spark-operator-controller-bb745cb-qj6vj 0/1 OOMKilled 5 16h
spark-operator-controller-bb745cb-qj6vj 0/1 CrashLoopBackOff 5 16hThe CrashLoopBackOff is self-reinforcing. The kubelet backs off exponentially between restarts (10s, 20s, 40s, up to 5 minutes). Each restart does a full LIST, caches all 700 ConfigMaps, exceeds the limit, and crashes again. The operator stays down until someone manually cleans up the hostile ConfigMaps or increases the memory limit (which just raises the bar for the next attack). There’s no self-healing path.
This matters because data scientists and ML engineers often have edit access to multiple namespaces. They create ConfigMaps routinely for experiment configs, hyperparameter sets, and pipeline parameters. A malicious user could disguise the attack as normal workload activity. And since the operator is the thing that’s crashing, the blast radius extends to every user on the cluster who depends on that operator.
The silent failure mode
OOMKill is actually the visible failure mode. On clusters where the operator has a higher memory limit (say, 2 GiB), the informer survives, but the initial LIST response can grow large enough to break HTTP/2 streams on the API server connection.
When an HTTP/2 stream breaks mid-response, it poisons the shared connection pool that client-go uses. Subsequent API calls on that connection hang indefinitely. The operator pod stays Running with zero restarts. It looks healthy from the outside. But one or more controllers are silently deadlocked, unable to make any API calls.
I’ve seen this cause an authentication controller to hang for nearly 2 hours on a production cluster before anyone noticed. No alerts fired because the pod was Running and passing basic health checks. The operator was technically alive but doing nothing.
This silent mode is arguably worse than OOMKill. At least OOMKill is loud. Monitoring catches it, on-call gets paged, someone investigates. A deadlocked controller looks healthy from every angle. Liveness probes pass (they check if the process is running, not if the controllers are making progress). Readiness probes pass (the HTTP server still responds). The pod shows Running with 0 restarts. The only symptom is that reconciliation stops, and depending on the operator, that might not be noticed for hours.
Things that look like they protect you but don’t
This is where experienced Go developers get tripped up. There are two common patterns that look like they filter the cache but don’t.
Predicates and event filters
You might think you’re safe if you have a predicate filtering events:
builder.Watches(&corev1.ConfigMap{},
handler.EnqueueRequestsFromMapFunc(mapToOwner),
builder.WithPredicates(predicate.NewPredicateFuncs(
func(obj client.Object) bool {
return obj.GetName() == "my-operator-config"
},
)),
)The predicate does filter events. Only events for my-operator-config will trigger your reconciler. But the predicate sits between the informer and the work queue. It’s a downstream filter. The informer itself still does a full LIST+WATCH on every ConfigMap in every namespace, deserializes each one into a corev1.ConfigMap struct, and holds them all in memory.
Your memory footprint is determined by what the informer watches, not by what your predicates let through to the reconciler. A predicate that filters 99.9% of events still leaves 100% of objects in the cache.
Think of it like a security camera system. Predicates are like software filters that only show you footage from certain cameras on your monitor. But every camera is still recording and storing video to disk. The filter decides what you see, not what gets recorded. To reduce storage, you need to turn off the cameras you don’t need, not just filter the display.
DisableFor on the client
controller-runtime’s client has a DisableFor option that looks like it turns off caching for specific types:
mgr, err := ctrl.NewManager(cfg, ctrl.Options{
Client: client.Options{
Cache: &client.CacheOptions{
DisableFor: []client.Object{
&corev1.ConfigMap{},
},
},
},
})For client.Get() and client.List() calls, this works as expected. Those calls bypass the cache and go straight to the API server. But if your controller setup also includes Owns(&corev1.ConfigMap{}) or Watches(&corev1.ConfigMap{}, ...), those directives create a completely independent informer through the controller builder. DisableFor has zero effect on controller builder informers. They’re separate code paths.
So you can have DisableFor set on ConfigMaps (thinking you’re bypassing the cache) while simultaneously having a Watches call that creates an unfiltered cluster-wide informer for the same type. Both are active. The DisableFor makes your explicit client.Get() calls go to the API server, but the Watches informer is still consuming memory for every ConfigMap in the cluster.
Why not just increase the memory limit?
Before diving into the fix, I want to address the obvious question: why not just give the operator more memory?
Two reasons. First, it’s an arms race you can’t win. If you set the limit to 2 GiB, an attacker creates 2000 ConfigMaps instead of 700. There’s no safe upper bound because users can always create more ConfigMaps. You’d need to set the limit higher than the total possible ConfigMap volume across all namespaces, which is impractical on a multi-tenant cluster.
Second, as I described above, higher memory limits don’t actually prevent the failure. They just change the failure mode from visible (OOMKill) to silent (HTTP/2 stream corruption and controller deadlock). That’s worse, not better.
The correct fix is to eliminate the unfiltered cache entirely.
The fix in 4 steps
Fixing this properly requires four steps. Each one matters, and skipping any of them creates either a regression or an upgrade failure.
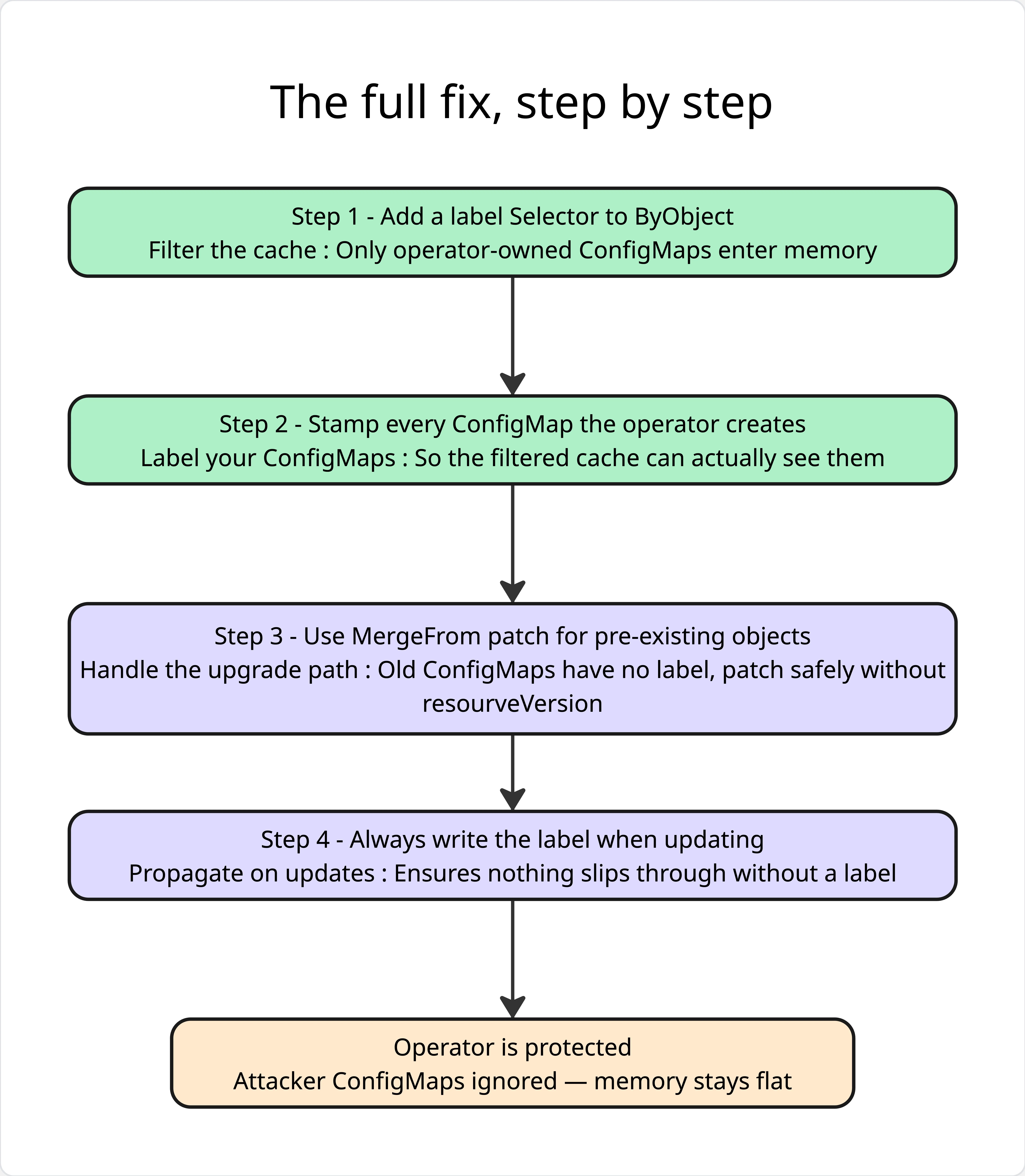
Step 1: Filter the cache
Add a label selector to restrict what the informer caches:
// Before (vulnerable):
&corev1.ConfigMap{}: {},
// After (fixed):
&corev1.ConfigMap{}: {
Label: labels.SelectorFromSet(labels.Set{
"sparkoperator.k8s.io/created-by-spark-operator": "true",
}),
},
Now the informer’s LIST call includes a labelSelector parameter. The API server only returns ConfigMaps with that label. Everything else is invisible to the operator. A user flooding the cluster with unlabeled ConfigMaps has zero impact on the operator’s memory footprint.
Step 2: Label your own ConfigMaps
Since the cache now filters by label, every ConfigMap your operator creates must carry the label. Otherwise your own operator can’t see its own ConfigMaps.
return &corev1.ConfigMap{
ObjectMeta: metav1.ObjectMeta{
Name: prometheusConfigMapName,
Namespace: app.Namespace,
Labels: map[string]string{
"sparkoperator.k8s.io/created-by-spark-operator": "true",
},
},
Data: configMapData,
}This is straightforward, but tedious. You need to audit every place in the codebase where ConfigMaps are constructed and make sure the label is present. Miss one and that ConfigMap becomes invisible to the operator after the fix is deployed. In the Spark Operator, there were multiple creation sites: Prometheus monitoring configs, Spark driver configs, and webhook-related configs. Each one needed the label.
A good approach is to grep for corev1.ConfigMap{ and &corev1.ConfigMap{ across the entire codebase, then verify each hit has the label in its ObjectMeta.
Step 3: Handle the upgrade path
This is the step most people forget, and it’s the one that causes production incidents during rollout.
Pre-existing ConfigMaps from the old operator version don’t have the label. After the upgrade, the filtered cache can’t see them. So client.Get() returns NotFound (the cache has no entry for the unlabeled object), but client.Create() returns AlreadyExists (the object exists in the API server, just not in the cache).
You can’t use client.Update() to fix this because Update requires a resourceVersion, which you get from client.Get(), which returns NotFound because the cache can’t see the object. Catch-22.
The fix uses a merge patch, which doesn’t require a resourceVersion:
if errors.IsAlreadyExists(createErr) {
base := &corev1.ConfigMap{
ObjectMeta: metav1.ObjectMeta{
Name: configMap.Name,
Namespace: configMap.Namespace,
},
}
desired := base.DeepCopy()
desired.Labels = map[string]string{
"sparkoperator.k8s.io/created-by-spark-operator": "true",
}
desired.Data = configMap.Data
return c.Patch(ctx, desired, client.MergeFrom(base))
}The merge patch adds the label and updates the data in one atomic operation. Once the label is applied, the filtered cache picks up the ConfigMap on its next sync, and subsequent client.Get() calls work normally. This only runs once per pre-existing ConfigMap during the first reconciliation after the upgrade.
Step 4: Propagate labels during updates
Make sure the label persists when your operator updates ConfigMaps. Without this, an update could accidentally drop the label (especially if the update replaces the entire labels map), making the ConfigMap invisible to the cache again.
cm.Data = configMap.Data
if cm.Labels == nil {
cm.Labels = map[string]string{}
}
cm.Labels["sparkoperator.k8s.io/created-by-spark-operator"] = "true"
return c.Update(ctx, cm)This is defensive coding. Even if your current update logic preserves labels, future changes might not. Explicitly setting the label on every update path guarantees it’s always present.
Results on a real cluster
I validated both the vulnerability and the fix on an OpenShift cluster. The test keeps the 700 flooded ConfigMaps in place between phases, so the patched operator has to survive the same hostile environment that crashed the unpatched version.
| Metric | Unpatched | Patched |
|---|---|---|
| Status | OOMKilled, CrashLoopBackOff | Running, 0 restarts |
| Memory | Exceeded 512 MiB (exit code 137) | 14 MiB, flat |
| 700 flooded ConfigMaps | All cached in memory | Completely ignored |
| Spark workloads | Denied (operator down) | Functioning normally |
The patched operator starts up, does its filtered LIST (which returns zero results because none of the flood ConfigMaps have the operator label), opens a filtered WATCH, and settles at 14 MiB of memory usage. The 700 hostile ConfigMaps are completely invisible to it. They might as well not exist.
The memory difference is dramatic: from exceeding 512 MiB and crashing to sitting at 14 MiB with room to spare. The fix doesn’t just mitigate the attack, it eliminates the entire attack surface. There’s no amount of unlabeled ConfigMaps an attacker can create that will affect the operator’s memory usage.
The 14 MiB figure is the operator’s baseline memory with its own ConfigMaps (which carry the label and are correctly cached) plus the controller-runtime framework overhead. During the test, I left the 700 hostile ConfigMaps in place and the patched operator ran for over an hour with stable memory. No growth, no spikes, no degradation. The filtered WATCH stream also never fires for the hostile ConfigMaps because they don’t match the label selector, so there’s zero CPU overhead from processing irrelevant events.
This is not just the Spark Operator
When I audited other controller-runtime operators for the same pattern, I found it in the majority of them. Not just with ConfigMaps, but with Secrets, Services, and other high-volume resource types that exist in large numbers on production clusters.
The Kubeflow Training Operator was independently reported by another engineer for the same vulnerability (kubeflow/trainer#3374), confirming this is systemic. The root cause is the same: ByObject caches everything when no selector is specified. An empty {} looks harmless but creates a cluster-wide informer.
Every controller-runtime operator should audit its cache configuration for unfiltered entries. Here’s what to look for:
# Find all ByObject configurations
grep -rn "ByObject" --include="*.go" .
# Find all Watches/Owns calls for common high-volume types
grep -rn "Watches\|Owns" --include="*.go" . | grep -i "configmap\|secret\|service\|endpoint"
# Find implicit cache creation via client.Get on non-cached types
grep -rn "client.Get\|r.Get\|r.Client.Get" --include="*.go" . | grep -i "configmap\|secret"If you see an empty {} next to any resource type that users can create (ConfigMaps, Secrets, Services, PVCs), you have this vulnerability. The same applies to Owns() and Watches() calls without corresponding cache filters, which Part 2 covers in detail.
What’s next
The upstream fix for the Spark Operator is at kubeflow/spark-operator#2878.
In Part 2: 5 anti-patterns that cause this vulnerability, I catalog the five distinct code patterns that create unfiltered informer caches, including paths that are completely invisible during code review (like client.Get() silently creating cluster-wide informers when the cache has no entry for a type). If you maintain a controller-runtime operator, that post will help you audit your entire codebase.
Both articles are also published on Red Hat Developer: