Why your operator caches everything in the cluster (5 anti-patterns)
In Part 1, I showed how an unfiltered ConfigMap cache took down the Kubeflow Spark Operator. Any user with standard edit permissions could flood the cluster with large ConfigMaps, and the operator would OOMKill into CrashLoopBackOff. We fixed that one and moved on.
Then I audited other controller-runtime operators and found the same pattern in the majority of them. Not just ConfigMaps: Secrets, Services, and other high-volume resource types. The Kubeflow Training Operator was independently reported by another engineer for the exact same issue (kubeflow/trainer#3374), confirming this is systemic.
This post catalogs the 5 anti-patterns that cause it, explains why each one fools experienced Go developers into thinking they’re protected, and provides fixes. Everything here applies equally to Secrets, which are typically more numerous on production clusters (ServiceAccount tokens, TLS certs, registry auth).
Quick recap: how informer caches work
If you’ve read Part 1, skip this section. The short version: when a controller-runtime operator needs to know about objects in the cluster, it sets up an informer. The informer does a full LIST of every matching object at startup, then opens a persistent WATCH connection for changes. Every object gets deserialized into a full Go struct and stored in memory.
No filters means every object of that type, across every namespace, in memory. A user with the standard edit ClusterRole can create ConfigMaps up to 1MB each. 700 of them is enough to OOMKill most operators.
And here’s the thing: OOMKill is actually the visible failure mode. On clusters where the operator has a higher memory limit, the LIST response can grow large enough to break HTTP/2 streams on the API server connection. This poisons the shared connection pool that client-go uses. Subsequent API calls on that connection hang indefinitely. The operator pod stays Running with zero restarts, looks healthy from the outside, but one or more controllers are silently deadlocked. No alerts fire because the pod is Running and passing health checks. I’ve seen this cause an authentication controller to hang for nearly 2 hours on a production cluster before anyone noticed.
Anti-pattern 1: “My predicate filters it, so I’m safe”
This is the most common misunderstanding. You write:
builder.Watches(&corev1.ConfigMap{},
handler.EnqueueRequestsFromMapFunc(mapToOwner),
builder.WithPredicates(predicate.NewPredicateFuncs(
func(obj client.Object) bool {
return obj.GetName() == "my-operator-config"
},
)),
)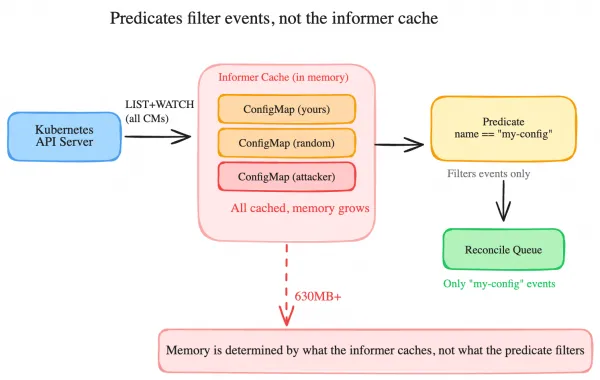
The intent: only watch a single ConfigMap named my-operator-config. The predicate filters everything else out. And it does filter, at reconciliation time. Events for other ConfigMaps won’t trigger your reconciler.
But the informer doesn’t know about your predicate. Predicates sit between the informer and the work queue. The informer still does a full LIST+WATCH on every ConfigMap in every namespace, deserializes each one, and holds them all in memory. Your predicate decides which events reach the reconciler, not which objects get cached.
Think of it like a security camera system. Predicates are software filters that only show you footage from certain cameras on your monitor. But every camera is still recording and storing video to disk. The filter decides what you see, not what gets recorded. To reduce storage, you need to turn off the cameras you don’t need.
WithEventFilter() has the same limitation. It’s a reconciliation-time gate, not a cache-time gate. A predicate that filters 99.9% of events still leaves 100% of objects in the cache. Your memory footprint is determined by what the informer watches, not by what your predicates let through.
The fix
If you only need to read a specific ConfigMap occasionally (like a CA bundle or operator config), don’t use Watches() at all. Use a direct API call through an uncached reader:
apiReader := mgr.GetAPIReader()
var caCM corev1.ConfigMap
if err := apiReader.Get(ctx, client.ObjectKey{
Namespace: "openshift-config-managed",
Name: "default-ingress-cert",
}, &caCM); err != nil {
return err
}No informer, no cache, no memory growth. The tradeoff is latency (roughly 50ms per API call vs roughly 1ms from cache), which is acceptable for resources you read once during reconciliation.
If you do need to react to changes in owned resources, keep the Watches() or Owns() call but add a label selector in the cache’s ByObject config so the informer only caches objects your operator actually created.
Anti-pattern 2: “I used DisableFor, so caching is off”
controller-runtime’s client has a DisableFor option:
mgr, err := ctrl.NewManager(cfg, ctrl.Options{
Client: client.Options{
Cache: &client.CacheOptions{
DisableFor: []client.Object{
&corev1.ConfigMap{},
},
},
},
})For client.Get() and client.List() calls, this works: those bypass the cache and go straight to the API server. So far so good.
But there’s a completely separate code path. When your controller setup includes:
func (r *MyReconciler) SetupWithManager(mgr ctrl.Manager) error {
return ctrl.NewControllerManagedBy(mgr).
For(&myv1.MyResource{}).
Owns(&corev1.ConfigMap{}). // creates an informer
Watches(&corev1.Secret{}, ...). // also creates an informer
Complete(r)
}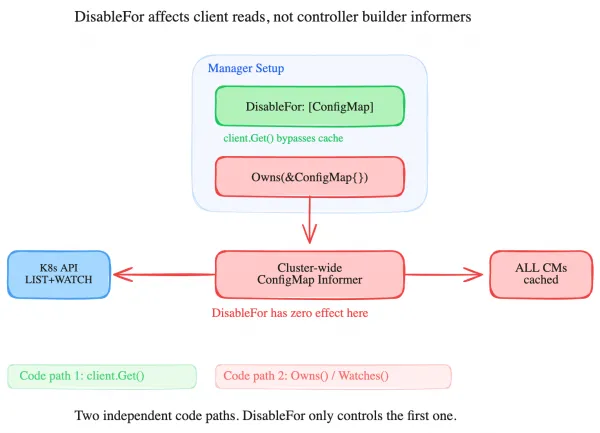
Owns() registers a ConfigMap informer through the controller builder. This is a completely independent code path from the client cache. The informer starts, watches every ConfigMap cluster-wide, and caches all of them. DisableFor has zero effect on it.
So you can have DisableFor set on ConfigMaps (thinking you’re bypassing the cache) while simultaneously having an Owns() call that creates an unfiltered cluster-wide informer for the same type. Both are active. The DisableFor makes your explicit client.Get() calls go to the API server, but the Owns() informer is still consuming memory for every ConfigMap in the cluster.
The fix
Two options depending on why you have Owns():
If you own ConfigMaps and need to reconcile when they change: keep Owns() but add a label selector to the ByObject cache config. This filters the informer at the API server level:
Cache: cache.Options{
ByObject: map[client.Object]cache.ByObject{
&corev1.ConfigMap{}: {
Label: labels.SelectorFromSet(labels.Set{
"app.kubernetes.io/managed-by": "my-operator",
}),
},
},
},If you’re using Owns() only for garbage collection: you don’t need it at all. Owner references handle garbage collection automatically through the Kubernetes garbage collector. The GC doesn’t need an informer. Remove the Owns() call entirely.
Anti-pattern 3: The invisible informer from client.Get()
This is the most dangerous one because it’s completely invisible during code review. No Watches(), no Owns(), just a regular client.Get():
func (r *MyReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
var secret corev1.Secret
if err := r.Client.Get(ctx, client.ObjectKey{
Namespace: req.Namespace,
Name: "some-tls-cert",
}, &secret); err != nil {
return ctrl.Result{}, err
}
// use secret.Data["tls.crt"]...
}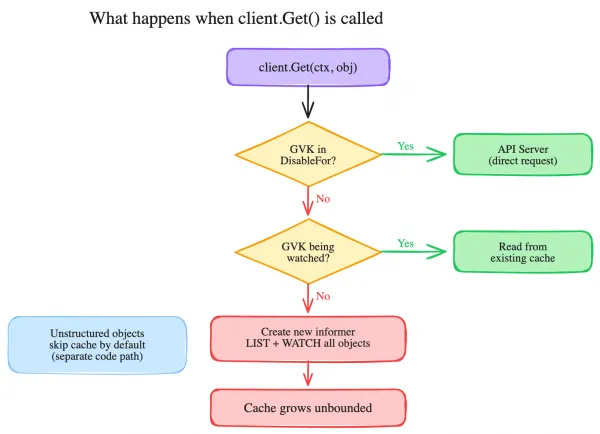
If corev1.Secret is not listed in your cache.Options.ByObject, here’s what happens the first time this runs:
r.Client.Get()routes to the cached client (the default)- The cache doesn’t have an informer for
Secretyet - controller-runtime creates a new cluster-wide Secret informer on the fly
- The informer does a full
LISTof every Secret in every namespace - All of them get deserialized and cached in memory
- Your
Get()returns the one Secret you asked for
Steps 2 through 5 happen silently, once, on the first access. You never asked for a cluster-wide informer, but you got one. There’s no log line, no warning, no indication in the code that this is happening. Someone reviewing the PR sees a straightforward client.Get() call and has no reason to suspect it triggers a full cluster-wide LIST and cache of every Secret.
I found one operator that had label selectors on 9 resource types in its ByObject config (Deployments, ConfigMaps, PVCs, ServiceAccounts, Services, NetworkPolicies, ClusterRoleBindings, RoleBindings, Roles) but omitted Secrets. A single client.Get() for a Secret somewhere in the reconciler triggered this exact anti-pattern: an implicit, unfiltered, cluster-wide Secret informer. All the careful work filtering 9 types was undermined by one missing entry.
The fix
Add the type to DisableFor so any client.Get() or client.List() call bypasses the cache entirely:
Client: client.Options{
Cache: &client.CacheOptions{
DisableFor: []client.Object{
&corev1.ConfigMap{},
&corev1.Secret{},
},
},
},Or add it to ByObject with a label selector if you need cached reads for that type.
The empty Namespaces trap
There’s a subtle gotcha with the ByObject config. You might try to restrict an informer to specific namespaces:
ByObject: map[client.Object]cache.ByObject{
&corev1.Secret{}: {
Namespaces: map[string]cache.Config{},
},
},An empty Namespaces map doesn’t mean “no namespaces.” It means “use the default,” which is cluster-wide. You need to explicitly list every namespace you want to watch. An empty map gives you the same unfiltered behavior as {}.
Anti-pattern 4: Everything is cluster-wide by default
controller-runtime’s cache has a DefaultNamespaces option:
Cache: cache.Options{
DefaultNamespaces: map[string]cache.Config{
"my-operator-ns": {},
},
}When set, informers only watch the listed namespaces. When not set (the default), every informer watches all namespaces. This is the default for every operator that doesn’t explicitly configure it.
Most operators can’t simply restrict to a single namespace because they manage resources across user namespaces. If your operator creates resources in 5 namespaces, but you don’t set DefaultNamespaces or per-resource label selectors, your ConfigMap informer watches ConfigMaps in all 500 namespaces on the cluster.
The fix
For single-namespace operators, DefaultNamespaces is the simplest and most effective protection:
Cache: cache.Options{
DefaultNamespaces: map[string]cache.Config{
operatorNamespace: {},
},
},For multi-namespace operators (which is most of them), label selectors in ByObject are the right fix. Label your owned resources and filter on that label:
ByObject: map[client.Object]cache.ByObject{
&corev1.ConfigMap{}: {
Label: labels.SelectorFromSet(labels.Set{
"app.kubernetes.io/managed-by": "my-operator",
}),
},
&corev1.Secret{}: {
Label: labels.SelectorFromSet(labels.Set{
"app.kubernetes.io/managed-by": "my-operator",
}),
},
},This gives you filtered informers across all namespaces without restricting namespace scope. The API server does the filtering server-side, so unlabeled objects never hit the wire, never get deserialized, and never consume memory in the operator.
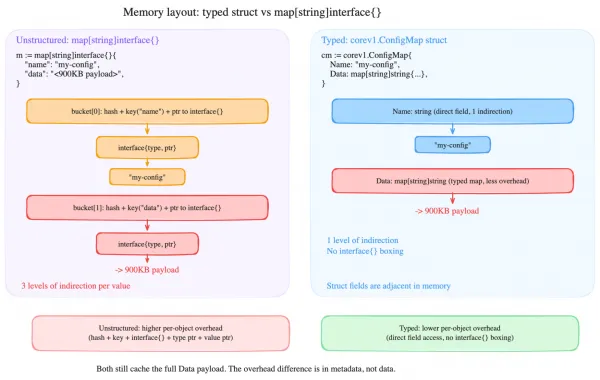
Anti-pattern 5: The typed/unstructured cache trap
controller-runtime maintains three completely separate caches:
- Typed cache: full Go structs (
corev1.ConfigMap,corev1.Pod) - Unstructured cache:
map[string]interface{}representations (unstructured.Unstructured) - Partial/Metadata cache: only
ObjectMeta(name, namespace, labels, annotations)
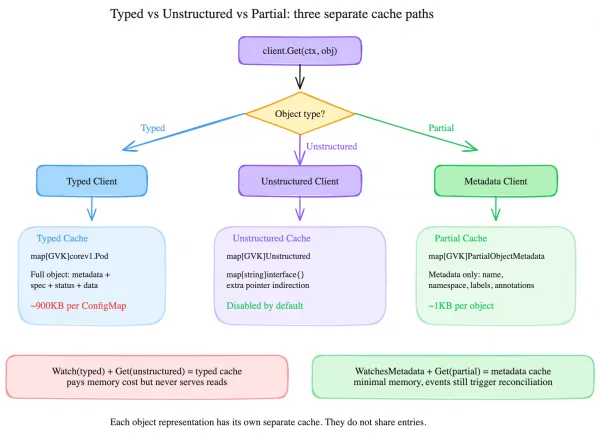
These caches don’t share entries. A ConfigMap cached as a typed corev1.ConfigMap is invisible to a client.Get() that requests an unstructured.Unstructured. They’re completely independent data stores, each with their own informers.
This creates a subtle memory waste scenario. If your controller uses Watches(&corev1.ConfigMap{}) for reconciliation triggers but reads ConfigMaps in your reconciler using an unstructured Get(), the typed cache pays the full memory cost of caching every matching ConfigMap, but none of those cached objects ever serve a read. The unstructured Get() either hits a separate unstructured cache (creating a second informer and doubling memory usage) or goes to the API server if the unstructured type isn’t cached.
The fix
Make sure your read path and your watch path use the same object representation. If you watch typed, read typed. If you watch unstructured, read unstructured.
Better yet, if you only need events to trigger reconciliation (you don’t read data from the watched objects), use WatchesMetadata():
builder.WatchesMetadata(&corev1.ConfigMap{},
handler.EnqueueRequestsFromMapFunc(mapToOwner),
)WatchesMetadata() creates a metadata-only informer that stores only ObjectMeta for each object. No spec, no data, no status. For a ConfigMap that’s 900KB of data, the metadata-only representation might be a few hundred bytes. If you’re watching ConfigMaps just to trigger reconciliation when one changes (and you read the actual data via an uncached reader), this reduces the cache footprint by orders of magnitude.
The complete fix: both code paths
Here’s the key insight that ties all five anti-patterns together. There are two independent code paths that create informers:
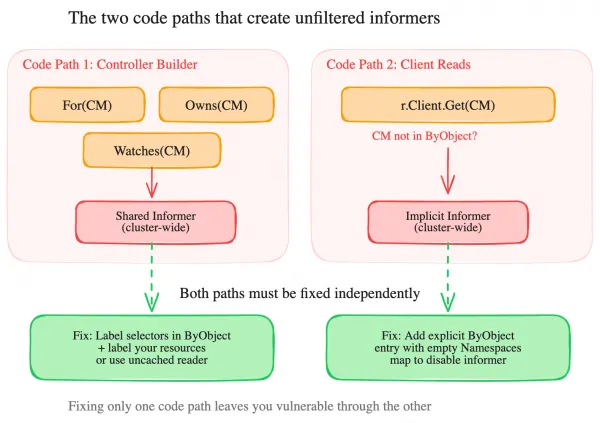
Code path 1: Controller builder registrations. For(), Owns(), and Watches() in your SetupWithManager() function. These are visible in code review. They create informers through the controller builder.
Code path 2: Implicit informers from client reads. client.Get() and client.List() calls anywhere in your reconciler. If the type isn’t in ByObject, the first call silently creates a cluster-wide informer. These are invisible during review.
To fully protect your operator, you need to handle both paths. Here’s the complete manager configuration that covers everything:
mgr, err := ctrl.NewManager(cfg, ctrl.Options{
Cache: cache.Options{
ByObject: map[client.Object]cache.ByObject{
// Code path 1: types used in For(), Owns(), Watches()
// Each one gets a label selector to filter the informer
&myv1.MyResource{}: {}, // your own CRD, always safe
&corev1.ConfigMap{}: {
Label: labels.SelectorFromSet(labels.Set{
"app.kubernetes.io/managed-by": "my-operator",
}),
},
&appsv1.Deployment{}: {
Label: labels.SelectorFromSet(labels.Set{
"app.kubernetes.io/managed-by": "my-operator",
}),
},
},
// Optional: strip large fields from cached objects to save memory
DefaultTransform: func(obj interface{}) (interface{}, error) {
if cm, ok := obj.(*corev1.ConfigMap); ok {
cm.ManagedFields = nil
return cm, nil
}
return obj, nil
},
},
Client: client.Options{
Cache: &client.CacheOptions{
// Code path 2: types used in client.Get()/List()
// that should NOT create implicit informers
DisableFor: []client.Object{
&corev1.Secret{},
&corev1.Service{},
},
},
},
})ByObject filters the explicit informers from code path 1. DisableFor prevents implicit informers from code path 2. DefaultTransform strips fields you don’t need (like ManagedFields) from cached objects to further reduce memory.
How to audit your operator in 5 minutes
Five grep commands. Run them from the root of your operator repo.
Step 1: Find all explicit cache configurations.
grep -rn "ByObject" --include="*.go" .Look for empty {} entries. Each one is an unfiltered cluster-wide informer.
Step 2: Find all controller builder registrations.
grep -rn "\.Owns\|\.Watches\|\.For(" --include="*.go" .Each result creates an informer. Cross-reference with Step 1 to verify every watched type has cache filtering.
Step 3: Find potential implicit informers.
grep -rn "\.Get(ctx\|\.List(ctx\|\.Get(r\.\|\.Client\.Get\|\.Client\.List" --include="*.go" .For each Get() or List() call, check if the target type is in ByObject (filtered) or DisableFor (bypassed). If it’s in neither, the first call will silently create an unfiltered cluster-wide informer.
Step 4: Check for high-volume types without filtering.
grep -rn "ConfigMap\|Secret\|Service\b\|Endpoints\|Event\b" --include="*.go" . \
| grep -v "_test.go" | grep -v "vendor/" | head -30These types exist in large numbers on production clusters. Any informer for these types without a label selector or namespace restriction is a potential problem.
Step 5: Check for predicate-only filtering.
grep -rn "WithPredicates\|WithEventFilter\|predicate\." --include="*.go" .If a Watches() call has predicates but no corresponding ByObject label selector, the predicate only filters events, not the cache. The informer still caches everything.
Bonus: ReaderFailOnMissingInformer
controller-runtime has a cache option that turns anti-pattern 3 from a silent memory bomb into a loud crash:
Cache: cache.Options{
ReaderFailOnMissingInformer: true,
}With this set, a client.Get() for a type that doesn’t have a pre-configured informer returns an error instead of silently creating one. This is excellent for development and testing. It forces you to explicitly declare every type the operator touches, either in ByObject (with filters) or DisableFor. No more surprise informers.
I recommend enabling this in development and CI. It surfaces anti-pattern 3 immediately as a test failure instead of letting it slip into production as a silent memory leak.
Anti-patterns summary
| # | Anti-pattern | Why it fools you | Actual behavior | Fix |
|---|---|---|---|---|
| 1 | Predicate filtering | ”My predicate only passes events I care about” | Predicates filter the work queue, not the cache. Full LIST+WATCH happens regardless. | Use apiReader for occasional reads, or ByObject label selectors for owned resources |
| 2 | DisableFor | ”I disabled caching for this type” | DisableFor only affects client.Get()/List(). Owns() and Watches() create independent informers. | Add label selectors to ByObject, or remove Owns() if only used for GC |
| 3 | Implicit client.Get() | “It’s just a Get call” | First Get() for an unconfigured type silently creates a cluster-wide informer | Add to DisableFor, or add to ByObject with label selector |
| 4 | No namespace scoping | ”It’s fine, we only read from a few namespaces” | Default is cluster-wide. All namespaces watched, all objects cached. | DefaultNamespaces for single-NS operators, label selectors for multi-NS |
| 5 | Typed/unstructured mismatch | ”I’m watching this type already” | Three separate caches (typed, unstructured, metadata) don’t share entries | Match watch and read representations. Use WatchesMetadata() when you only need triggers |
Tips and best practices
Use WatchesMetadata() for trigger-only watches
If you watch a type just to trigger reconciliation (you don’t read its data from the cache), use WatchesMetadata() instead of Watches(). It creates a metadata-only informer that stores only ObjectMeta: name, namespace, labels, annotations. For data-heavy types like ConfigMaps and Secrets, this reduces per-object memory from hundreds of KB to a few hundred bytes.
// Instead of this (caches full ConfigMap data):
builder.Watches(&corev1.ConfigMap{}, handler)
// Use this (caches only metadata):
builder.WatchesMetadata(&corev1.ConfigMap{}, handler)Use DefaultTransform to strip fields
DefaultTransform runs on every object before it enters the cache. Use it to strip fields you never read:
Cache: cache.Options{
DefaultTransform: func(obj interface{}) (interface{}, error) {
// Strip ManagedFields from everything
if accessor, err := meta.Accessor(obj); err == nil {
accessor.SetManagedFields(nil)
}
// Strip annotations you don't need
if accessor, err := meta.Accessor(obj); err == nil {
annotations := accessor.GetAnnotations()
delete(annotations, "kubectl.kubernetes.io/last-applied-configuration")
accessor.SetAnnotations(annotations)
}
return obj, nil
},
},kubectl.kubernetes.io/last-applied-configuration is one of the worst offenders. It stores a full JSON copy of the object in an annotation. For a ConfigMap with 500KB of data, this annotation alone adds another 500KB+ to the in-memory representation. Stripping it in DefaultTransform can cut memory usage nearly in half for annotation-heavy objects.
Set memory limits with informer cost in mind
When setting memory limits for your operator pod, don’t just measure the baseline. Estimate the informer cost:
- Each cached object consumes roughly 1.5-2x its serialized size (Go struct overhead)
- A
corev1.ConfigMapwith 1KB of data is about 2KB in the cache - A
corev1.Secretwith 4KB of data (typical TLS cert) is about 6-8KB in the cache - Multiply by the number of matching objects across all watched namespaces
For example, if your operator watches Secrets with a label selector, and you expect 200 matching Secrets averaging 4KB serialized, plan for about 200 * 8KB = 1.6MB of cache overhead for that type alone. Compare that to an unfiltered watch on a cluster with 5,000 Secrets: 5000 * 8KB = 40MB just for Secrets.
Use the NewInformer hook for observability
controller-runtime’s cache supports a NewInformer hook that lets you intercept informer creation:
Cache: cache.Options{
NewInformer: func(
gvk schema.GroupVersionKind,
obj runtime.Object,
resyncPeriod time.Duration,
indexers cache.Indexers,
) cache.SharedIndexInformer {
log.Info("Creating informer", "gvk", gvk)
return cache.NewSharedIndexInformer(/* ... */)
},
},This is useful for debugging. If you’re not sure which informers your operator creates, add logging here to see exactly what gets instantiated at startup. Any informer you didn’t expect is either an implicit creation from client.Get() (anti-pattern 3) or an overlooked Owns()/Watches() registration.
What’s next
This is Part 2 of a two-part series:
- Part 1: Protect your Kubernetes Operator from OOMKill covers the vulnerability, exploitation, and fix for the Spark Operator
- Part 2 (this post) catalogs the five anti-patterns that cause this across the controller-runtime ecosystem
Both articles are also published on Red Hat Developer:
- Part 1: Protect your Kubernetes Operator from OOMKill
- Part 2: 5 anti-patterns that cause Kubernetes operator vulnerabilities
If you maintain a controller-runtime operator, run the 5-step audit. It takes 5 minutes and the results will probably surprise you.